入门第一课 虚拟机搭建和安装hadoop及启动
大数据生态系统
1. 存储
- Hadoop hdfs
2. 计算引擎
- map/reduce v1
- map/reduce v2 (map/reduce on yarn)
- Tez
- spark
3. Impala Presto Drill 直接跑在hdfs上
pig(脚本方式) hive(SQL语言) 泡在map/reduce上
hive on Tez/sparkSQL
4. 流式计算 - storm
5. kv store
Cassandra mongodb hbase
6. Tensorflow Mahout
7. Zookeeper Protobuf
8. sqoop kafka flume……
五个软件
- virtualbox
- centos.org
- hadoop
- jdk
- xshell(xftp)
- pan.baidu.com/s/1i5jzxVR
虚拟机安装
- VirtualBox
- centOS 7
- 网络设置ipconfig
特别需要注意的地方:
将虚拟机的网络设置为host-only,我因为忘了设置成host-only,导致新建的虚拟机和宿主机怎么都ping不通,浪费了我一些时间。
选中虚拟机–>设置–>网络vim /etc/sysconfig/network
NETWORKING=yes
GATEWAY=192.168.56.1- vim /etc/sysconfig/network-sripts/ifcfg-enp0s3
TYPE=Ethernet
IPADDR=192.168.56.100
NETMASK=255.255.255.0 - 修改主机名hostnamectl set-hostname master (主机名千万不能有下划线!)
- 如果需要虚拟机上网还需要配置/etc/resolv.conf
- 重启网络service network restart
systemctl restart network - 检查ssh服务的状态 service network restart
- 互相ping,看是否测试成功,若不成功,注意防火墙的影响。关闭windows或虚拟机的防火墙。systemctl stop firewalld system disable firewalld
win10:192.168.56.1
Linux:192.168.56.100
- 使用XShell登陆
- 下载安装Xftp
- 检查ssh服务状态systemctl status sshd (service sshd status),验证使用XShell是否能登陆成功。
- 将hadoop和jdk上传到虚拟机
进入文件夹,安装JDK
rpm -ivh ./xxxxx.jdk,验证 i=install v=verble h=打出#号
rpm -qa | grep jdk,在命令行中敲java命令,确认jdk已经安装完成
jdk默认安装在/usr/java目录下安装hadoop,解压缩和配置
cd /usr/local
tar –xvf ./hadoop-2.7.2.tar.gz
把目录修改为hadoop mv hadoop-2… hadoop- 告诉Hadoop JDK的目录,so修改hadoop-env.sh
vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
修改export JAVA_HOME 语句为 export JAVA_HOME=/usr/java/default - 把/usr/hadoop/bin和/usr/hadoop/sbin设到PATH中
vi /etc/profile
追加 export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin - 执行修改的文件 source etc/profile
测试hadoop命令是否可以直接执行,任意目录下敲hadoop
cd h 代表了省略
- 告诉Hadoop JDK的目录,so修改hadoop-env.sh
关闭虚拟机shutdown -h now,复制3份
Xshell发送键到所有会话,分别修改虚拟机的ip和hostname,确认互相能够ping通,用ssh登陆,同时修改所有虚拟机的/etc/hosts,确认使用名字可以ping通
关闭各个机器上的防火墙 (master / slaves)
systemctl stop firewalld
systemctl disable firewalld修改Hadoop配置文件启动 /usr/local/hadoop/etc/hadoop/core-site.xml,指明namenode的信息
1
2
3
4
5
6
7
8<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
ctrl+c退出
clear清屏
Tab补全
- 修改4台机器的/etc/hosts,让他们通过名字认识对方,测试一下互相用名字可以ping通。
192.168.56.100 master
192.168.56.101 slave1
192.168.56.102 slave2
192.168.56.103 slave3 修改master下的/usr/local/hadoop/etc/hadoop/slaves
slave1
slave2
slave3
这样,master就可以知道slave1,2,3对应的IP了。启动namenode和datanode
master上需要格式化namenode,执行指令:
hadoop namenode -format
启动master上的namenode,在master上执行:
hadoop-daemon.sh start namonode
启动slave上的datanode,在每个slave上执行:
hadoop-daemon.sh start datanode
- 使用jps查看namenode和datanode的启动情况。
至此,一个master,三个slave的hadoop集群搭建完成并启动成功。
业务需求变更永无休止,技术前进就永无止境!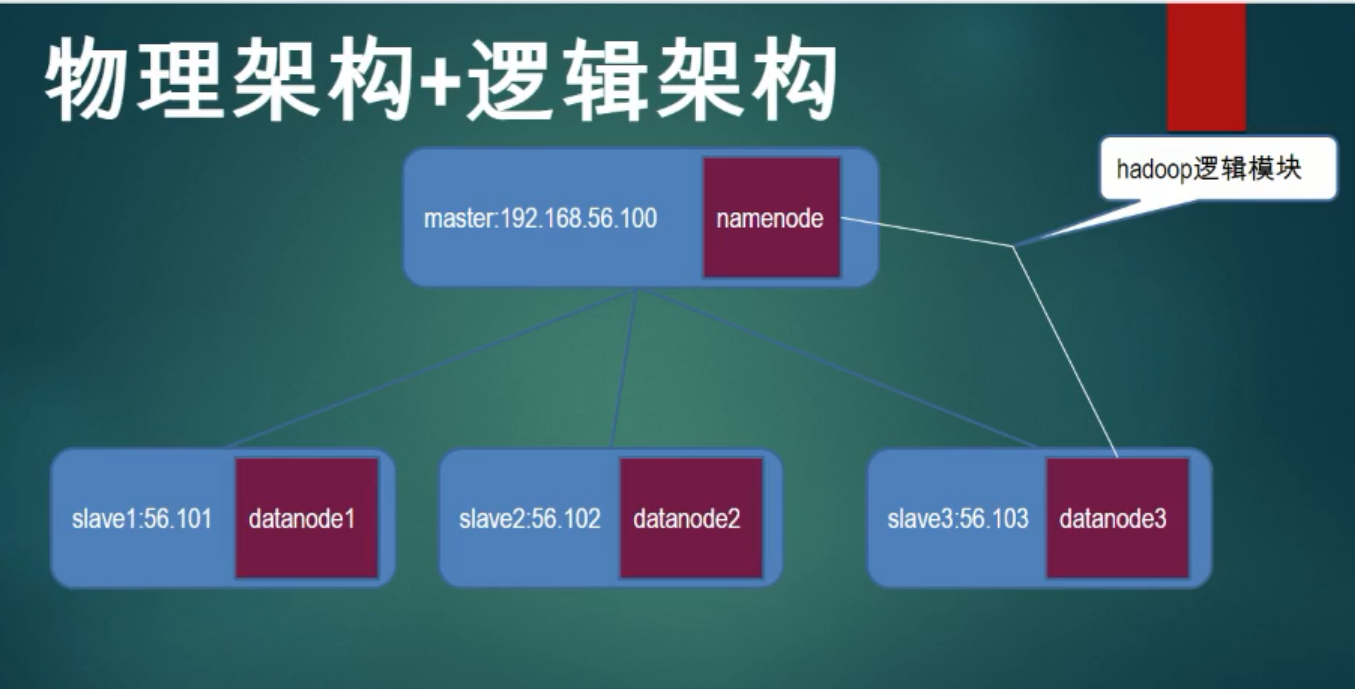 Hadoop.png
Hadoop.png
入门第二课 hdfs集群集中管理和hadoop文件操作
namenode存储文件系统元数据(文件目录结构、分块情况、每款位置、权限等)存在内存中
分块存储,备份两份,一般默认128M,所以Hadoop适合大文件。
如果要查IP地址,就在开始,运行中输入cmd,回车,输入“ipconfig /all”,再回车,就可以看到。
(1)观察集群配置情况
[root@master ~]# hdfs dfsadmin -report
(2)web界面观察集群运行情况
使用netstat命令查看端口监听
[root@master ~]# netstat -ntlp
浏览器地址栏输入:http://192.168.56.100:50070
(3)对集群进行集中管理
a) 修改master上的/usr/local/hadoop/etc/hadoop/slaves文件
[root@master hadoop]# vim slaves
#编辑内容如下
slave1
slave2
slave3
先使用hadoop-daemon.sh stop namenode(datanode)手工关闭集群。
b) 使用start-dfs.sh启动集群
[root@master hadoop]# start-dfs.sh
发现需要输入每个节点的密码,太过于繁琐,于是需要配置免密ssh远程登陆。
在master上用ssh连接一台slave,需要输入密码slave的密码,
[root@master hadoop]# ssh slave1
需要输入密码,输入密码登陆成功后,使用exit指令退回到master。
c) 免密ssh远程登陆
生成rsa算法的公钥和私钥
[root@master hadoop]# ssh-keygen -t rsa (然后四个回车)
进入到/root/.ssh文件夹,可看到生成了id_rsa和id_rsa.pub两个文件。
使用以下指令完成免密ssh登陆,拷贝公钥到每个服务器,包括本身
[root@master hadoop]# ssh-copy-id slaveX
使用stop-dfs.sh停止集群,然后使用start-dfs.sh启动集群。
[root@master ~]# stop-dfs.sh
[root@master ~]# start-dfs.sh
(3)修改windows上的hosts文件,通过名字来访问集群web界面
编辑C:\Windows\System32\drivers\etc\hosts
192.168.56.100 master
然后就可以使用http://master:50070代替http://192.168.56.100:50070
(4) 使用hdfs dfs 或者 hadoop fs命令对文件进行增删改查的操作
1 hadoop fs -ls /
2 hadoop fs -put file /
3 hadoop fs -mkdir /dirname
4 hadoop fs -text /filename
5 hadoop fs -rm /filename
将hadoop的安装文件put到了hadoop上操作如下
[root@master local]# hadoop -fs put ./hadoop-2.7.3.tar.gz /
通过网页观察文件情况
(5)将dfs-site.xml的replication值设为2
replication参数是分块拷贝份数,hadoop默认为3。
也就是说,一块数据会至少在3台slave上都存在,假如slave节点超过3台了。
/usr/local/hadoop/etc/hadoop
vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>10000</value>
</property>
</configuration>
配置文件查询:安装包hadoop-2.7.3\hadoop-2.7.3\share\doc\hadoop\index.html
core-default.html
hdfs-default.html
mapred-default.html
yarn-default.html
为了方便测试,同时需要修改另外一个参数dfs.namenode.heartbeat.recheck-interval,这个值默认为300s,
将其修改成10000,单位是ms,这个参数是定期间隔时间后检查slave的运行情况并更新slave的状态。
可以通过 hadoop-2.7.3\share\doc\hadoop\index.html里面查找这些默认的属性
修改完hdfs-site.xml文件后,重启hadoop集群,
stop-dfs.sh #停止hadoop集群
start-dfs.sh #启动hadoop集权
hadoop -fs put ./jdk-8u91-linux-x64.rpm / #将jdk安装包上传到hadoop的根目录
到web页面上去观察jdk安装包文件分块在slave1,slave2,slave3的存储情况
hadoop-daemon.sh stop datanode #在slave3上停掉datanode
等一会时间后(大概10s,前面修改了扫描slave运行情况的间隔时间为10s),刷新web页面
观察到slave3节点挂掉
hadoop-daemon.sh start datanode #在slave3上启动datanode
然后再去观察jdk安装包文件分块在slave1,slave2,slave3的存储情况
入门第三课 java访问hdfs
(1)关于hdfs小结
hadoop由hdfs + yarn + map/reduce组成,
hdfs是数据库存储模块,主要由1台namenode和n台datanode组成的一个集群系统,
datanode可以动态扩展,文件根据固定大小分块(默认为128M),
每一块数据默认存储到3台datanode,故意冗余存储,防止某一台datanode挂掉,数据不会丢失。
HDFS = NameNode + SecondaryNameNode + journalNode + DataNode
hdfs的典型应用就是:百度云盘
(2)修改hadoop.tmp.dir默认值
hadoop.tmp.dir默认值为/tmp/hadoop-${user.name},由于/tmp目录是系统重启时候会被删除,所以应该修改目录位置。
修改core-site.xml(在所有节点上都修改)
[root@master ~]# vim core-site.xml
修改完namenode和datanode上的hadoop.tmp.dir参数后,需要格式化namenode,在master上执行:
[root@master ~]# hdfs namenode -format
[root@master ~]# stop-dfs.sh
[root@master ~]# start-dfs.sh
hadoop-daemon.sh start datanode
通过java程序访问hdfs,就把HDFS集群当成一个大的系统磁盘就行了!
安装myeclipse,破解,导入jar包,在master中创建文件,上传到/目录下。
windows上的权限系统和linux上的权限系统,测试期间为了简单起见可以关闭权限检查 在namenode的hdfs-site.xml上,添加配置:
重新启动namenode:
[root@master ~]# hadoop-daemon.sh stop namenode
[root@master ~]# hadoop-daemon.sh start namenode
(5) 使用FileSyste类来读写hdfs
package com.hadoop.hdfs;
import java.io.FileInputStream;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HelloHDFS {
public static Log log = LogFactory.getLog(HelloHDFS.class);
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.56.100:9000");
conf.set("dfs.replication", "2");//默认为3
FileSystem fileSystem = FileSystem.get(conf);
boolean success = fileSystem.mkdirs(new Path("/yucong"));
log.info("创建文件是否成功:" + success);
success = fileSystem.exists(new Path("/yucong"));
log.info("文件是否存在:" + success);
success = fileSystem.delete(new Path("/yucong"), true);
log.info("删除文件是否成功:" + success);
/*FSDataOutputStream out = fileSystem.create(new Path("/test.data"), true);
FileInputStream fis = new FileInputStream("c:/test.txt");
IOUtils.copyBytes(fis, out, 4096, true);*/
FSDataOutputStream out = fileSystem.create(new Path("/test2.data"));
FileInputStream in = new FileInputStream("c:/test.txt");
byte[] buf = new byte[4096];
int len = in.read(buf);
while(len != -1) {
out.write(buf,0,len);
len = in.read(buf);
}
in.close();
out.close();
FileStatus[] statuses = fileSystem.listStatus(new Path("/"));
log.info(statuses.length);
for(FileStatus status : statuses) {
log.info(status.getPath());
log.info(status.getPermission());
log.info(status.getReplication());
}
}
}
这是一个maven项目,pom.xml文件为:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
复习:
- hadoop分为几个逻辑组件?
a. hdfs yarn mapred
b. hdfs-> namenode datanode secondarynamenode journalnode - hdfs的典型结构? 主从结构(物理结构+逻辑结构)
- hdfs如何实现横向扩展?加一台机器作为datanode,链接到namenode上
- hdfs的典型应用设计?360网盘 百度网盘
- 网盘中“保存到我的网盘”会复制一份数据到你的网盘吗? 不会,我的网盘作为一个namenode。
没讲什么:
- 安全与权限 kerberos
- secondary namenode -> check point namenode
- HA实现
- Federation超大规模数据中心
入门第四课 Yarn和Map/Reduce配置启动和原理讲解
分布式计算
设计原则:移动计算,而不是移动数据
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
Caffe (卷积神经网络框架)
Caffe,全称Convolutional Architecture for Fast Feature Embedding。
caffe是一个清晰,可读性高,快速的深度学习框架。作者是贾扬清,加州大学伯克利的ph.D,现就职于Facebook。caffe的官网是http://caffe.berkeleyvision.org/。
- 配置计算调度系统Yarn和计算引擎Map/Reduce,所有机器同时配置。
- namenode上配置mapred-site.xml
mapreduce.framework.name
yarn
yarn-site.xml的配置
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
- 启动yarn集群start-yarn.sh
- jps观察启动结果
- 可以使用yarn-daemon.sh单独启动resourcemanager和nodemanager
- 通过网页http://master:8088/观察yarn集群
- 实验:建立一个wordcount.txt文件,利用map reduce计算里面单词的数量。
hadoop fs -mkdir /input
hadoop fs -put wordcount.txt /input/
find /usr/local/hadoop -name example.jar 查找示例文件 - 通过hadoop jar xxx.jar wordcount /input /output来运行示例程序
- 通过网页来观察该job的运行情况
- hadoop job -kill job_id –> mapred job -kill job_id mapred job -list
- 经验:yarn-site如果是集中启动,其实只需要在管理机上配置一份即可,但是如果单独启动,需要每台机器一份,在网页上可以看到当前机器的配置,以及这个配置的来源
入门第五课 java编写mapreduce程序
以上任何对环境变量的修改,都需要重新启动电脑使配置生效,因此可将所需软件全部安装配置好后再重启电脑。
- java开发map_reduce程序
- 配置系统环境变量HADOOP_HOME,指向hadoop安装目录(如果你不想招惹不必要的麻烦,不要在目录中包含空格或者中文字符)
把HADOOP_HOME/bin加到PATH环境变量(非必要,只是为了方便) - 如果是在windows下开发,需要添加windows的库文件
a. 把盘中共享的bin目录覆盖HADOOP_HOME/bin
b. 如果还是不行,把其中的hadoop.dll复制到c:\windows\system32目录下,可能需要重启机器 - 建立新项目,引入hadoop需要的jar文件
代码WordMapper:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordMapper extends Mapper<LongWritable,Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for(String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
代码WordReducer:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class WordReducer extends Reducer
@Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { long count = 0; for(IntWritable v : values) { count += v.get(); } context.write(key, new LongWritable(count)); }}
代码Test:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Test {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setMapperClass(WordMapper.class);
job.setReducerClass(WordReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, "c:/bigdata/hadoop/test/test.txt");
FileOutputFormat.setOutputPath(job, new Path("c:/bigdata/hadoop/test/out/"));
job.waitForCompletion(true);
}
}
把hdfs中的文件拉到本地来运行
FileInputFormat.setInputPaths(job, “hdfs://master:9000/wcinput/“);
FileOutputFormat.setOutputPath(job, new Path(“hdfs://master:9000/wcoutput2/“));
注意这里是把hdfs文件拉到本地来运行,如果观察输出的话会观察到jobID带有local字样
同时这样的运行方式是不需要yarn的(自己停掉yarn服务做实验)在远程服务器执行
conf.set(“fs.defaultFS”, “hdfs://master:9000/“);
conf.set(“mapreduce.job.jar”, “target/wc.jar”);
conf.set(“mapreduce.framework.name”, “yarn”);
conf.set(“yarn.resourcemanager.hostname”, “master”);
conf.set(“mapreduce.app-submission.cross-platform”, “true”);FileInputFormat.setInputPaths(job, “/wcinput/“);
FileOutputFormat.setOutputPath(job, new Path(“/wcoutput3/“));
如果遇到权限问题,配置执行时的虚拟机参数-DHADOOP_USER_NAME=root- 也可以将hadoop的四个配置文件拿下来放到src根目录下,就不需要进行手工配置了,默认到classpath目录寻找
- 或者将配置文件放到别的地方,使用conf.addResource(.class.getClassLoader.getResourceAsStream)方式添加,不推荐使用绝对路径的方式
建立maven-hadoop项目:
4.0.0
mashibing.com
maven
0.0.1-SNAPSHOT
wc hello mp
<properties>
<project.build.sourceencoding>UTF-8</project.build.sourceencoding>
<hadoop.version>2.7.3</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
</project>
配置log4j.properties,放到src/main/resources目录下
log4j.rootCategory=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[QC] %p [%t] %C.%M(%L) | %m%n
Hive入门
- Hive入门
tar -xvf 解压Hive,到/usr/local目录,将解压后的目录名mv为hive
设定环境变量HADOOP_HOME,HIVE_HOME,将bin目录加入到PATH中
vim /etc/profile
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
export HADOOP_HOME=/usr/local/hadoop
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bincd /usr/local/hive/conf
cp hive-default.xml.template hive-site.xml
修改hive.metastore.schema.verification,设定为false
创建/usr/local/hive/tmp目录,替换${system:java.io.tmpdir}为该目录
替换${system:user.name}为rootschematool -initSchema -dbType derby
会在当前目录下简历metastore_db的数据库。
注意!!!下次执行hive时应该还在同一目录,默认到当前目录下寻找metastore。
遇到问题,把metastore_db删掉,重新执行命令
实际工作环境中,经常使用mysql作为metastore的数据- 启动hive
- 观察hadoop fs -ls /tmp/hive中目录的创建
- show databases;
use default;
create table doc(line string);
show tables;
desc doc;
select * from doc;
drop table doc; - 观察hadoop fs -ls /user
- 启动yarn
- load data inpath ‘/wcinput’ overwrite into table doc;
select from doc;
select split(line, ‘ ‘) from doc;
select explode(split(line, ‘ ‘)) from doc;
select word, count(1) as count from (select explode(split(line, ‘ ‘)) as word from doc) w group by word;
select word, count(1) as count from (select explode(split(line, ‘ ‘)) as word from doc) w group by word order by word;
create table word_counts as select word, count(1) as count from (select explode(split(line, ‘ ‘)) as word from doc) w group by word order by word;
select from word_counts;
dfs -ls /user/hive/… - 使用sougou搜索日志做实验
- 将日志文件上传的hdfs系统,启动hive
hadoop fs -put sougou.dic / - create table sougou (qtime string, qid string, qword string, url string) row format delimited fields terminated by ‘,’; 划界区域被逗号终止
desc sougou; 查看建立的sougou表 - load data inpath ‘/sougou.dic’ into table sougou;
- select count(*) from sougou;
- create table sougou_results as select keyword, count(1) as count from (select qword as keyword from sougou) t group by keyword order by count desc;
- select * from sougou_results limit 10;
概念
用类似SQL语言的方式做计算
将SQL语句查询,转换为MapReduce操作,省去Java编程
应用场合:
静态数据分析:数据不会频繁变化,不需要实时结果响应
OLAP OLTP
Spark
内存计算引擎
使用scala开发
支持Java scala python开发接口
下载
地址spark.apache.org
安装
复制一台单独的虚拟机,名c
修改其ip,192.168.56.200
修改其hostname为c,hostnamectl set-hostname c
修改/etc/hosts加入对本机的解析
重启网络服务 systemctl restart network
上传spark安装文件到root目录
解压spark到/usr/local下,将其名字修改为spark
本地运行模式
使用spark-submit提交job
cd /usr/local/spark
./bin/spark-submit –class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.11-2.1.0.jar 10000使用spark-shell进行交互式提交
创建root下的文本文件hello.txt
./bin/spark-shell
再次连接一个terminal,用jps观察进程,会看到spark-submit进程
sc
sc.textFile(“/root/hello.txt”)
val lineRDD = sc.textFile(“/root/hello.txt”)
lineRDD.foreach(println)
观察网页端情况
val wordRDD = lineRDD.flatMap(line => line.split(“ “))
wordRDD.collect
val wordCountRDD = wordRDD.map(word => (word,1))
wordCountRDD.collect
val resultRDD = wordCountRDD.reduceByKey((x,y)=>x+y)
resultRDD.collect
val orderedRDD = resultRDD.sortByKey(false)
orderedRDD.collect
orderedRDD.saveAsTextFile(“/root/result”)
观察结果
简便写法:sc.textFile(“/root/hello.txt”).flatMap(.split(“ “)).map((,1)).reduceByKey(+).sortByKey().collect
sc.textFile(“/root/wordcount.txt”).flatMap(.split(“ “)).map((,1)).reduceByKey(+).sortByKey(false).saveAsTextFile(“/root/result”)使用local模式访问hdfs数据
start-dfs.sh
spark-shell执行:sc.textFile(“hdfs://192.168.56.100:9000/hello.txt”).flatMap(.split(“ “)).map((,1)).reduceByKey(+).sortByKey().collect (可以把ip换成master,修改/etc/hosts)
sc.textFile(“hdfs://192.168.56.100:9000/hello.txt”).flatMap(.split(“ “)).map((,1)).reduceByKey(+).sortByKey().saveAsTextFile(“hdfs://192.168.56.100:9000/output1”)spark standalone模式
在master和所有slave上解压spark
修改master上conf/slaves文件,加入slave
修改conf/spark-env.sh,export SPARK_MASTER_HOST=master
复制spark-env.sh到每一台slave
cd /usr/local/spark
./sbin/start-all.sh
在c上执行:./bin/spark-shell –master spark://192.168.56.100:7077 (也可以使用配置文件)
观察http://master:8080
spark on yarn模式
spark mesos模式
zookeeper
讲啥
- zookeeper是什么,有什么用
- 安装、配置、启动、监控
- java api
- HA的开发
- cap理论/paxos算法
怎么讲
大篇理论,很少实践
实践中穿插理论学习
一致 有头 数据树
Google三论文:GFS、BigTable、MapReduce
2、安装配置(注意:集群的所有机器都需要设置)
下载zookeeper-3.4.10.tar.gz
解压:tar xvf zookeeper-3.4.10.tar.gz
配置
切换到/zookeeper/conf目录:/usr/local/zookeeper-3.4.10/conf (我的路径)
server.n=xxx.xxx.xx:2888:3888
拷贝:cp zoo_sample.cfg zoo.cfg
修改zoo.cfg:vim zoo.cfg
dataDir=/tmp/zookeeper (数据存储位置,生产环境需要修改,这个是linux的临时目录,可能会被删除)
在配置文件底部添加一下内容:我这个配置了域名,如果没有配置域名就用ip。
server.1=master:2888:3888
server.2=slave2:2888:3888
server.3=slave3:2888:3888
修改数据文件
切换/tmp目录:cd /tmp
创建zookeeper目录:mkdir zookeeper
切换至zookeeper目录:cd /tmp/zookeeper
创建myid文件:vim myid
master上,输入1保存;slave2,输入2保存;slave3,输入3保存。
启动、观测
切换至/zookeeper/bin目录:/usr/local/zookeeper-3.4.10/bin
服务端
启动:./zkServer.sh start
查看:./zkServer.sh status
停止:./zkServer.sh stop
jps(查看状态)
2289 QuorumPeerMain
2302 Jps
zookeeper集群建议使用奇数。其中有一个leader,其余是follower。
客户端 .
./zkCli.sh -server master:2181
create /tank tankservers
create /tank/server1 server1info
create /tank/server2 server2info
create /tank/server3 server3info
ls /tank
get /tank
set /tank tankserversinfo
get /tank
delete /tank/server3
