简介
Spark作为新一代大数据计算引擎,因为内存计算的特性,具有比hadoop更快的计算速度。本教程涉及Spark基础概念RDD,KeyValueRDD,RDD的常用Transformation和Action操作等。
第1章 Spark介绍
1-1 Spark简介 (03:59)
- Spark是一个快速且通用的集群计算平台。
- Spark是快速的:
Spark扩充了流行的MapReduce计算模型;
Spark是基于内存的计算。 - Spark是通用的:
Spark的设计容纳了其它分布式系统拥有的功能;
批处理,迭代式计算,交互查询和流处理等。
优点:降低维护成本。 - spark是高度开放的 :
提供了python,java,Scala,SQL的API和丰富的内置库。
与其他的大数据工具整合的很好。
快速:秒和分级别,相比hadoop的分和时
通用:应用场景多
快速:
1、扩充hadoop的Mapreduce计算模型
2、基于内存计算章节
通用:
1、容纳其他分布式系统功能,具有批计算,迭代式计算,交互查询和流处理
2、高度开发,提供多yu8yan的API,具有丰富的内置库
1-2 Spark生态介绍 (04:25)
spark历史:伯克利实验室研究项目,基于Hadoop的Mapreduce机制,引入内存管理机制,提高了迭代式计算和交互式中的效率。
spark组件:
spark core:spark基本功能,包括任务调度,内存管理,容错机制
内部定义了RDDs(弹性分布式数据集),提供多个APIs调用,为其他组件提供底层服务
spark sql:spark处理结构化数据的库,类似Hive SQL,MySql,主要为企业提供报表统计
spark streaming:实时数据流处理组件,类似Storm,提供API操作实时流数据,企业中用来从Kafka中接收数据做实时统计
Mlib:机器学习功能包,包括聚类,回归,模型评估和数据导入。同时支持集群平台上的横向扩展
Graphx:处理图的库,并进行图的并行计算
Cluster Manager是:spark自带的集群管理
Spark紧密集成的优点:
Spark底层优化了,基于Spark底层的组件,也得到了相应的优化。
紧密集成,节省了各个组件组合使用时的部署,测试等时间。
向Spark增加新的组件时,其他组件,立刻享用新组建的功能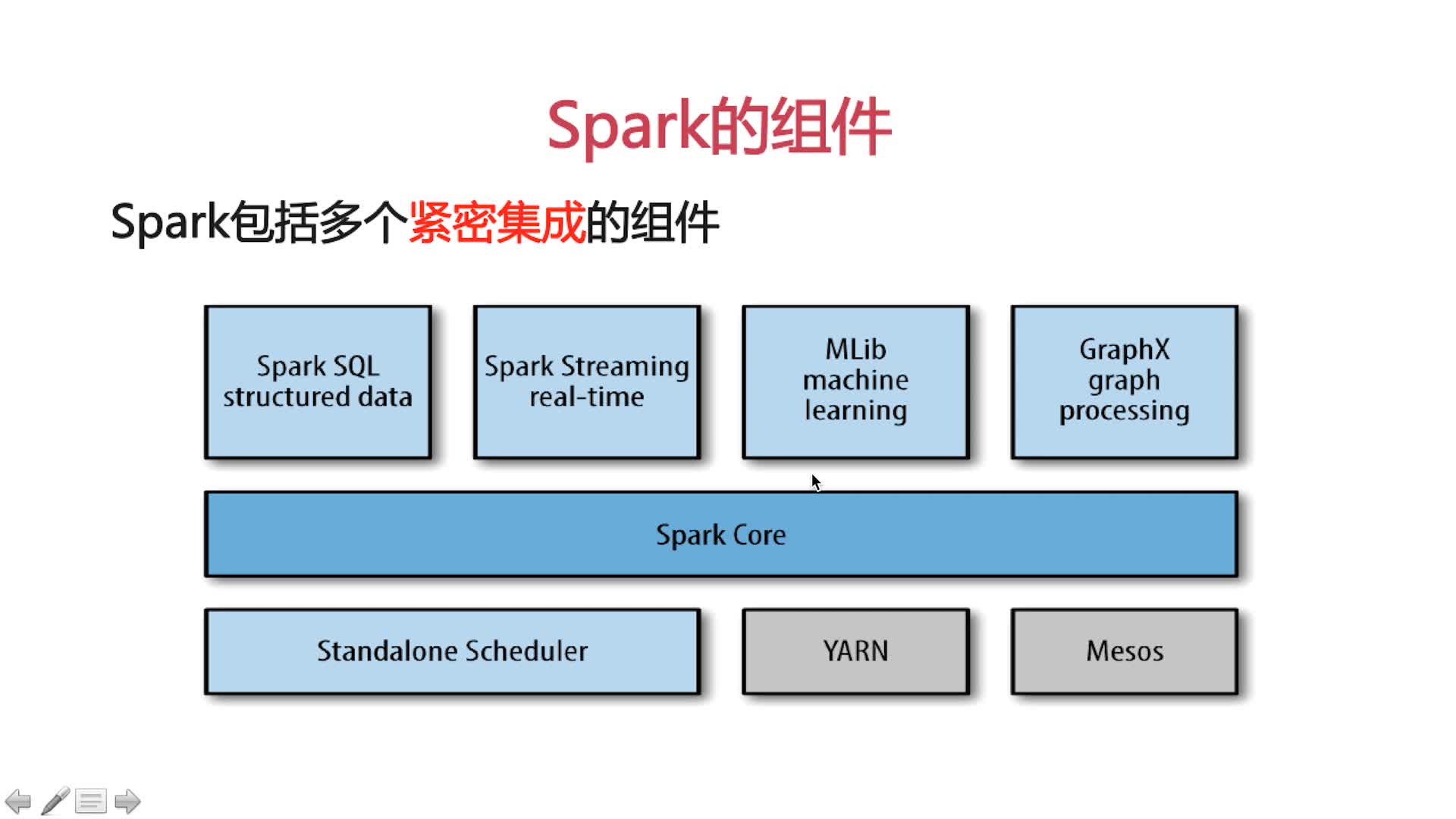
1-3 Spark与Hadoop的比较 (01:58)
Hadoop应用场景:
离线处理,时效性要求不高的场景:Hadoop中间数据落到硬盘上,导致Hadoop处理大数据时,时效性不高,时间在几分钟到几小时不等,但数据可以存储。
Spark应用场景:
时效性要求高的场景和机器学习:Spark基于内存,中间数据多在内存中,数据处理块,但Spark不具备hdfs存储功能,需借助hdfs
Doug Cutting 的观点:
这是个生态系统,每个组件都有其作用,各姗其职即可,
Spark不具有HDFS的存储能力,要借助HDFS等持久数据
大数据将会孕育出更多的新技术
第2章 Spark的下载和安装
2-1 spark安装 (10:19)

1、下载
wget http://mirror.bit.edu.cn/apache/spark/spark-2.2.1/spark-2.2.1-bin-hadoop2.7.tgz
2、解压缩
tar -zxvf spark-2.2.1-bin-hadoop2.7.tgz
3、改文件夹名字
mv spark-2.2.1-bin-hadoop2.7 spark
4、Spark Shell
Python Shell: bin/pyspark
Scala Shell: bin/spark-shell
进入使用:./spark-shell(因为这是执行文件)
spark shell 实例
建立一个文件夹testfile,新建文件helloSpark1
2
3
4Hello Spark!
Hello Scala!
Hello HanKin!
Hello HeJian!
val lines = sc.textFile(“../../testfile/helloSpark”)
lines.count() 显示文件中行数
lines.first() 显示文件中第一行的内容
把文本文件加载成RDD复制给lines的RDD
修改日志级别
spark-2.2.1-bin-hadoop2.7/conf/log4j.properties.template
cp log4j.properties.template log4j.properties
修改为log4j.rootCategory=WARN, console
RDD
第3章 开发第一个Spark程序
3-1 Spark开发环境搭建 (10:39)
- First, make sure you have the Java 8 JDK installed.
- Then, install Scala:
wget https://downloads.lightbend.com/scala/2.12.4/scala-2.12.4.tgz
tar -zxvf scala-2.12.4.tgz
mkdir scala
配置环境变量
sudo vim /etc/profile1
2
3
4
5#define hejian's environment variable
export SCALA_HOME=/home/hejian/scala/scala-2.12.4
export PATH=$PATH:$SCALA_HOME/bin
export SPARK_HOME=/home/hejian/spark/spark-2.2.1-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
3-2 开发第一个Spark程序 (18:13)
配置ssh无秘钥登陆
ssh-keygen
.ssh下有个公钥文件,将其放置authorized_keys中,这个文件夹是自己创建的
改变文件权限
启动集群:
启动master ./sbin/start-master.sh
启动worker ./bin/spark-class
提交作业 ./bin/spark-submit
启动master
./sbin/start-master.sh
启动worker
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://sklse:7077
提交作业
./bin/spark-submit –master spark://sklse:7077 –class WordCount /home/hejian/spark/scala.jar
./bin/spark-submit –master spark://sklse:7077 –class RecommendMusic /home/hejian/parallelcompute/parallelcompute.jar
地址相关路径
http://192.168.201.17:8080/
http://192.168.201.171:8081/
第4章 Rdds
4-1 Rdds介绍 (17:25)
Driver program:包含了main方法
sparkContext:链接spark集群,一般直接使用shell创建好的对象sc即可
rdds:弹性分布数据集,spark如果大数据量时会自动将片分配到每一个节点上,各个片的总名称就是rdds 对象
创建rdds的两种对象:
1.使用sc.prilize对象
2.使用sc.textFile()加载外部对象
3.scala:匿名函数和类型推断。
line2.Filter(line=>line.contains(“world”))
即line2通过Filter的方法将每一行赋值给line,然后line在调用contains方法确认哪一行是否包含有world,这个单词,有则返回给line2.
1 | val lines = sc.textFile("/home/hejian/spark/testfile/helloSpark") |
4-2 RDDs基本操作之Transformations(一) (13:05)
rdd.transfomat操作:
1.map操作:将一个rdd变成一个可以和原来不同的内容排序的rdd
2.fileter:返回一个只符合条件的rdd
3.flatMap:将数据进行压扁生成一个新的rdd
1 | RDD 基本操作 Transformation(转换) |
4-3 RDDs基本操作之Transformations(二) (06:44)
rdd transformations(转换二)操作:集合运算
1.distinct :去除重复
2.subturast: rdd1.subtruast(rdd2),rdd1中有的,而rdd2中没有的
3.union。并集:rdd1.union(rdd2),取rdd1和rdd2中所有的数据
4.innter:交集:取rdd1与rdd2相同的部分
1 | val rdd1 = sc.parallelize(Array("coffe", "coffe", "panda", "monky", "tea")) |
4-4 RDD基本操作之Action (07:09)
Action 操作:返回最终的结果的操作
- Collect()遍历整个RDD 向drive program返回RDD的内容 需要单机内存能够容纳下(因为要拷贝给driver,一般测试使用),大数据的时候,使用saveAsTextFile() action保存文件中去。
- raduce() 接收一个函数,作用在RDD两个类型相同的元素上,返回新元素。可以实现RDD中元素的累加,计数,和其他类型的聚集操作。val sum=rdd.reduce((x,y)=>x+y)。
- top()根据RDD中的数据的比较器
- take(n) 返回RDD的n个元素(同时尝试访问最少的partitions)返回结果是无序的,一般测试使用。
- foreach()计算RDD中的每个元素,但不返回到本地。可以配合println()友好的打印出数据。
1 | val rdd = sc.parallelize(Array(1,2,3,3)) |
4-5 RDDS的特性 (08:09)
RDDS的特性
RDDS的血统关系图,Spark维护着RDDS之间的依赖关系以及创建关系,叫做血统关系图,Spark使用血统关系图来计算每个RDD的需求和恢复丢失的数据。
延迟计算,没有action,转换操作没有意义。
持久化:如果想重复利用一个RDD,可以使用RDD.persist()来持久化到缓存中,因为默认每次在RDDS上action操作时,Spark都要重新计算RDDS
4-6 KeyValue对RDDs(一) (13:35)
创建KeyValue对RDDs:
使用map()函数,返回key/value对
例如,包含数行数据的RDD,把每行数据的第一个单词作为keys1
2
3
4
5
6
7
8
9val rdd = sc.textFile("/home/hejian/spark/testfile/helloSpark")
val rdd2 = rdd.map(line=>(line.split(" ")(0), line))
rdd2.foreach(println)
val rdd3 = sc.parallelize(Array((1,2), (3,4), (3,6)))
val rdd4 = rdd3.reduceByKey((x,y)=>x+y)
rdd4.foreach(println)
val rdd5 = rdd3.groupByKey()
rdd5.foreach(println)


4-7 KeyValue对RDDs(二) (17:44)
1 | val scores = sc.parallelize(Array(("jake", 80.0), ("jake", 85.0), ("jake",90.0), ("mike", 85.0), ("mike", 92.0), ("mike", 90.0))) |
