关于封面
九带犰狳(Dasypus novemcinctus),是一种广泛分布于中北美及南美洲的哺乳动物。在拉丁文中,novemcinctus 的字面意思是“九条带子”(位于腹部可伸缩甲壳后方),实际上九带犰狳身上的“带子”数量通常为 7~11 条。产自南美洲的三带犰狳是唯一一种在遇到危险时可将身体团成球状来保护自身的犰狳,其他种类的犰狳则由于甲壳太多无法做到这点。
前言
作者朋友:Cathy O’Neil
作者:Rachel Schutt
本书资料:数据集、练习题等
动物书:Github地址
第1章 简介:什么是数据科学

数据科学和大数据

思维实验:可以通过数据科学的手段来定义数据科学吗?
- 使用文本挖据模型
- 使用聚类算法
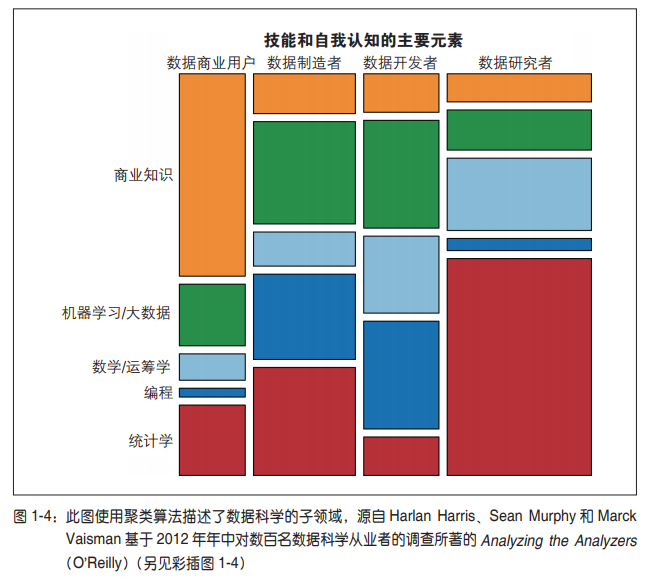
第2章 统计推断、探索性数据分析和数据科学工作流程
总体和样本
- 在统计推断中,总体并不特指人口,它指的是一组特定的对象或单位。
- 所谓样本,是指在总体中选取的一个子集,用 n 来表示。研究者记录下样本的观察数据,根据样本特征推断总体的情况。
- 采样
- 偏差
- 噪声
描述大数据的特征:大数据中的4V原则。这4V是指容量(Volume)、种类(Variety)、速度(Velocity)和价值(Value)。
N = 全部 & N = 1
建模
模型是人工设计的,用于将无关紧要的细节排除或抽象化。在进行模型分析时,研究者必须关注这些被省略的细节。
- 数据模型(data model),一种存储数据的结构,这属于数据库管理员的研究领域。
- 统计学中的模型
数学公式里一般使用希腊字母表示参数,拉丁字母表示数据。
概率分布
概率分布是统计模型的基础。
人的身高服从正态分布,正态分布是一种钟形曲线,也叫高斯分布,以数学家高斯的名字命名。
别以各自的发现者的名字命名(比如泊松分布、韦伯分布等),另外一些曲线,如伽玛分布、指数分布,则是以描述它们的数学方程式命名。
拟合模型是指用观察数据估计模型参数的过程。以数据为依据,近似模拟现实中产生数据的数学过程。拟合模型经常要引入各种优化方法和算法,例如最大似然估计等,来确定参数。
过拟合是指使用数据去估计模型的参数时,得到的模型并不能模拟现实情况,在样本以外的数据上效果不好。
探索性数据分析(EDA)
在探索性数据分析中,没有假设,也没有模型。这里的“探索性”是指你对待解问题的理解会随着研究的深入不断变化的。
探索性数据分析的基本工具是图、表和汇总统计量。一般来说,探索性数据分析是一种系统性分析数据的方法,它展示了所有变量的分布情况(利用盒形图)、时间序列数据和变换变量,利用散点矩阵图展示了变量两两之间的关系,并且得到了所有的汇总统计量。换句话说,就是要计算均值、最小值、最大值、上下四分位数和确定异常值。
探索性数据分析不仅是一组工具,更是一种思维方式:要怎么看待和数据之间的关系。
1 | 多大才是大 |
2.2.2 练习:探索性数据分析
有 如 下 31 个 数 据 文 件:nyt1.csv、nyt2.csv…nyt31.csv, 可 以 从 https://github.com/oreillymedia/doing_data_science 下载。每一个数据文件记录了《纽约时报》5 月份每天出现在主页上的广告和广告的点击次数,当然,这组数据是我们伪造的。数据的每一行代表了一个用户,数据共有 5 列,分别为:年龄、性别(0 = 女性,1 = 男性 )、广告显示次数、点击次数、是否登录。
数据加载成功后,就可以开始进行探索性数据分析了。
(1) 创建一个新变量 age_group ,按年龄将用户离散化,分为 “<18”、”18-24”、”25-34”、”35-44”、”45-54”、”55-64”、”65+” 总共 7 组。
(2) 对于每天的记录有以上操作。
• 对这 7 组用户,分别绘出点击率分布图 ( 点击率 = 点击次数 / 广告显示次数 )。
• 定义一个新变量,基于用户的点击行为将用户分类。
• 探索性地分析这些数据,从图形和数量两方面比较各用户组之间的差异(比如小于18 岁的男性和小于 18 岁的女性,或者已登录用户和未登录用户等)。
• 创建用于描述数据的各种统计量、矩阵。可能的度量项目有点击率、分位数、平均值、中位数、方差、最大值等,可以在每个用户组中单独计算这些统计量。要有所取舍,想一想随着时间的推移,哪些才是重要的、值得去记录的,这样可以压缩数据,同时不失准确地记录用户行为。
(3) 现在延长你所分析的时间,将数日内的矩阵和分布情况用图形表示出来。
(4) 描述并解释你发现的模式。
提示
不要将所有数据一次性读入内存。当你某天终于将代码写好时,一次只加载一个数据文件,处理它,输出相关的矩阵和变量,将结果存入一个数据框。在加载下一个文件时,记得移除上一个文件。之所以这样做,是为了让你思考在多个机器之间共享数据时该如何处理。
2.4 思维实验:如何模拟混沌
洛伦兹水车是一种摩天轮式的精妙装置,它由等间距的叶轮组成,绕轴旋转。每个叶轮下方都有一个小孔,设想一下水流从水车的正上方倾泻而下,从小孔中漏出的水会打到其他叶片上。调整水的流速,会发现叶轮一会儿正转,一会儿反转,呈现一种混沌的状态。
2.5.2 练一练:RealDirect公司的数据策略
因为现在还没有数据供你分析(通常在初创型公司中,产品这时还处于开发阶段),此时,你应该借助于一些辅助数据来获取对市场的认识。比如,可以去如下网站下载一些数据文件:https://github.com/oreillymedia/doing_data_science。
你可以使用部分或全部的数据文件。
• 第一个挑战:加载和清理数据。然后进行探索性数据分析,找出哪些数据中有异常值和缺失值,你会采取何种方式处理它们?最后,确保将数据格式转换为你想要的格式,诸如你认为整数类型的值应该确保其类是整型等。
• 当数据整理干净后,继续探索性分析,将数据间的关系用图形展示出来,将数据在(i) 空间和 (ii) 时间两个维度上进行对比。如果你时间充裕,可以试着找找这些数据里面是否蕴含着什么有意思的模式。
(3) 将你的发现总结成一份简报汇报给 CEO。
(4) 作为数据科学家工作的一部分,经常需要向那些不是数据科学家的人发表讲演,因此理想情况下,你需要掌握一些沟通的技巧,可以将你要表达的信息准确传达给对方。你能想到还应该和哪些人进行交流吗?
(5) 大多数人不是房地产行业或电子商务的“领域专家”。
• 跨出自己的舒适区,学会在一个不同的环境中采集数据是否给了你一些启示?使得你知道如何在自己的领域内行事。
• 有时候“领域专家”有他们专有的词汇。Doug 是否使用了一些他领域内的专有词汇是你所不理解的(“comps”“open houses”“CPC”)?有时候,如果你不明白一些专家正在使用的词汇,会妨碍你搞清楚问题。养成提问的好习惯,因为迟早你会碰
到一些你不明白的事,这需要持之以恒。
(6) Doug 提到他的公司并不是必须要有一个数据策略。也没有指定数据策略的业界标准。在你做这个练习的过程中,考虑一下是否有一些你想推荐的最佳实践,可以为电子商务或者你自己的领域指定数据策略提供帮助。
第3章 算法
高效的算法是准备和处理数据的基础,算法的执行可以是顺序的,也可以是并发的。就数据科学来说,以下三类算法是必须了解的。
(1) 数据清理和预处理的算法。比如排序、MapReduce、Pregel。
我们将这类算法称为数据工程,我们将用一章内容专门介绍这类算法,然而,这不是本书的重点。这并不代表你永远不会用到它们,只是作为一类算法,本书并不予以特殊强调。
(2) 用于参数估计的最优化算法。比如 Stochastic Gradient Descent(随机梯度下降)、Newton’s Method(牛顿法)和 Least Squares(最小二乘法)。
(3) 机器学习算法。
3.1机器学习算法
机器学习算法的应用主要有三个大舞台:预测、分类和聚类。
一般来讲,机器学习是人工智能的基础,比如图像识别、语音识别、推荐系统、排名和个性化推荐系统技术——这些都是打造数据产品的基础。
- 关于参数的解释
- 置信区间
- 显式假设的角色
统计模型会对数据的生成过程和数据的分布做出一些明确的假设(称作显式假设),
3.2三大基本算法
3.2.1线性回归模型
从根本上来说,当你想表示两个变量间的数学关系时,就可以使用线性回归。当你使用它时,你首先假设输出变量(有时称为响应变量、因变量或标签)和预测变量(有时称为自变量、解释变量或特征)之间存在线性关系。当然这种线性关系也可能存在于一个输出变量和数个预测变量之间 )。
到底是算法还是模型?
