0、学习资料
1、PyPI
PyPI(Python Package Index)是 Python 官方的第三方库的仓库,所有人都可以下载第三方库或上传自己开发的库到 PyPI。PyPI 推荐使用 pip 包管理器来下载第三方库。
https://docs.python.org/3/library/
https://pypi.org/search/
2、在GitHub上使用ipynb
GitHub能直接看,但有时候可能加载慢或加载不出来,所以使用第三方工具。
网站:https://nbviewer.jupyter.org/
分享:http://nbviewer.ipython.org/github/
3、机器学习算法
机器学习最大的特点是利用数据而不是指令来进行各种工作,其学习过程主要包括:数据的特征提取、数据预处理、训练模型、测试模型、模型评估改进等几部分。
机器学习算法可以分为传统的机器学习算法和深度学习。传统机器学习算法主要包括以下五类:
回归:建立一个回归方程来预测目标值,用于连续型分布预测
分类:给定大量带标签的数据,计算出未知标签样本的标签取值
聚类:将不带标签的数据根据距离聚集成不同的簇,每一簇数据有共同的特征
关联分析:计算出数据之间的频繁项集合
降维:原高维空间中的数据点映射到低维度的空间中
人工神经网络
深度学习
4、最小二乘法
5、常见的机器学习算法
(1)线性回归:找到一条直线来预测目标值
回归是指确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,通过建立一个回归方程(函数)来估计特征值对应的目标变量的可能取值。
房屋预测、电影票房预测、预测客户终生价值
(2)逻辑回归:找到一条直线来分类数据
逻辑回归虽然名字叫回归,却是属于分类算法,是通过Sigmoid函数将线性函数的结果映射到Sigmoid函数中,预估事件出现的概率并分类。Sigmoid是归一化的函数,可以把连续数值转化为0到1的范围,提供了一种将连续型的数据离散化为离散型数据的方法。
因此,逻辑回归从直观上来说是画出了一条分类线。位于分类线一侧的数据,概率>0.5,属于分类A;位于分类线另一侧的数据,概率<0.5,属于分类B。
疾病预测、预测消费者是否购买商品、预测贷款者未来是否会违约
(3)K-近邻:用距离度量最相邻的分类标签
通常k是不大于20的整数。
返回前k个点所出现频率最高的类别作为当前点的预测分类。
电影场景分类、影片分类、手写数字识别
(4)朴素贝叶斯:选择后验概率最大的类为分类标签
条件概率、先验概率、后验概率。
文本分类、垃圾文本过滤,情感判别,多分类实时预测
(5)决策树:构造一棵熵值下降最快的分类树
采用的是自顶向下的递归方法,选择信息增益最大的特征作为当前的分裂特征。
用户分级评估、贷款风险评估、选股、投标决策
(6)支持向量机(SVM):构造超平面,分类非线性数据
一般的数据是线性不可分的,可以通过核函数,将数据从二维映射到高维,通过超平面将数据切分。
垃圾邮件识别、手写识别、文本分类、选股
(7)K-means:计算质心,聚类无标签数据
随机生成k个初始点作为质心;将各个簇中的数据求平均值,作为新的质心,重复上一步,直到所有的簇不再改变。
客户价值细分,精准投资
(8)关联分析:挖掘啤酒与尿布(频繁项集)的关联规则(沃尔玛)
比较常见的一种关联算法是FP-growth算法。关联规则、支持度、置信度。
营销策略
(9)PCA降维:减少数据维度,降低数据复杂度
降维是指将原高维空间中的数据点映射到低维度的空间中。因为高维特征的数目巨大,距离计算困难,分类器的性能会随着特征数的增加而下降;减少高维的冗余信息所造成的误差,可以提高识别的精度。
比较常用的是主成分分析算法(PCA)。
(10)人工神经网络:逐层抽象,逼近任意函数
(11)深度学习:赋予人工智能以璀璨的未来
深度学习是机器学习的分支,是对人工神经网络的发展。
传统机器学习特征处理和预测分开,特征处理一般需要人工干预完成。这类模型称为浅层模型,或浅层学习,不涉及特征学习,其特征主要靠人工经验或特征转换方法来抽取。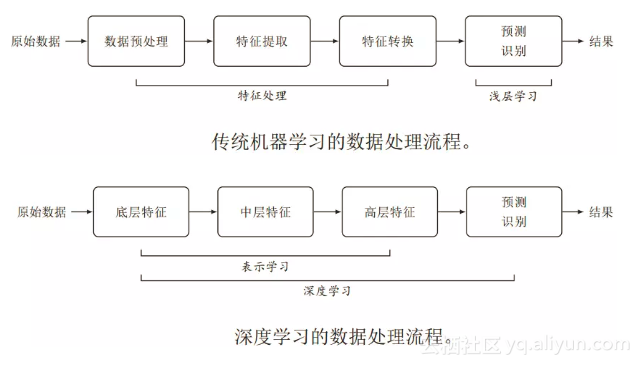
一个深层结构的优点是可以增加特征的重用性,从而指数级地增加表示能力。从底层特征开始,一般需要多步非线性转换才能得到较为抽象的高层语义特征。这种自动学习出有效特征的方式称为“表示学习”。
图像识别、语音识别、机器翻译、自动驾驶、金融风控、智能机器人等。
6、Anaconda:初学Python、入门机器学习的首选
NumPy:提供了矩阵运算的功能,其一般与Scipy、matplotlib一起使用,Python创建的所有更高层工具的基础,不提供高级数据分析功能
Scipy:依赖于NumPy,它提供便捷和快速的N维向量数组操作。提供模块用于优化、线性代数、积分以及其它数据科学中的通用任务。
Pandas:基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的,包含高级数据结构,以及和让数据分析变得快速、简单的工具
Matplotlib:Python最著名的绘图库
其中, Scikit-Learn是Anaconda中集成的开源机器学习工具包,主要涵盖分类,回归和聚类算法,可以直接调用传统机器学习的算法进行使用。同时Anaconda也兼容Google开发的第二代人工智能系统TensorFlow,进行深度学习的开发。
学习态度和学习风格内容都很符合胃口。
技术大牛https://cuijiahua.com/
贵有恒,何必三更起五更睡;最无益,只怕一日暴十寒。
努力,是为了将运气成分降到最低。
L1范数和L2范数的区别
L1正则化和L2正则化,或者L1范数和L2范数。可以看做是损失函数的惩罚项。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,因此可以用于特征选择。
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合。
OneHotEncoder独热编码和 LabelEncoder标签编码
OneHotEncoder:给特征的每个取值分配一个bit位。
LabelEncoder:给特征的每个取值分配下标从0开始,然后转换为相应的连续下标。
pd.set_option(‘display.max_columns’, None) # 强制显示所有属性值
pd.to_datetime(data[‘FFP_DATE’])
d_ffp = pd.to_datetime(data[‘FFP_DATE’])
d_load = pd.to_datetime(data[‘LOAD_TIME’])
res = d_load - d_ffp # 相减得天数
res.head()
np.map
np.filter
离散系数
离散系数又称变异系数,是统计学当中的常用统计指标。离散系数是测度数据离散程度的相对统计 量,主要是用于比较不同样本数据的离散程度。离散系数大,说明数据的离散程度也大;离散系数小,说明数据的离散程度也小。
离散系数是衡量资料中各观测值离散程度的一个统计量。当进行两个或多个资料离散程度的比较时,如果度量单位与平均数相同,可以直接利用标准差来比较。如果单位和(或)平均数不同时,比较其离散程度就不能采用标准差,而需采用标准差与平均数的比值(相对值)来比较。
标准分数
也叫z分数,是一种具有相等单位的量数。它是将原始分数与团体的平均数之差除以标准差所得的商数,是以标准差为单位度量原始分数离开其平均数的分数之上多少个标准差,或是在平均数之下多少个标准差。它是一个抽象值,不受原始测量单位的影响,并可接受进一步的统计处理。
标准分数是一种不受原始测量单位影响的数值。其作用除了能够表明原数据在其分布中的位置外,还能对未来不能直接比较的各种不同单位的数据进行比较。如比较各个学生的成绩在班级成绩中的位置或比较某个学生在两种或多种测验中所得分数的优劣。
主办方将对B榜获奖团队进行代码审核,代码需具有通用性和普适性,一旦发现作弊行为,即刻取消参赛及获奖资格。
a = [‘1’, ‘2’, ‘3’]
b = [‘4’, ‘5’]
c = a + b
c
列表相加是直接弄在一起
还有这种删除
del data[‘click’]
必须自己新建文件夹
